Hard to believe but I think this is the simplest you can manage:
long millisSinceEpoch = timestamp.getTime();
Instant instant = Instant.ofEpochMilli(millisSinceEpoch)
OffsetDateTime dt = OffsetDateTime.ofInstant(instant, ZoneId.of("UTC"))
Yikes.

Adventures in Computer Programming – bakert@gmail.com
Hard to believe but I think this is the simplest you can manage:
long millisSinceEpoch = timestamp.getTime();
Instant instant = Instant.ofEpochMilli(millisSinceEpoch)
OffsetDateTime dt = OffsetDateTime.ofInstant(instant, ZoneId.of("UTC"))
Yikes.
(Based on Stack Overflow tag count and upward trend as proportion of Stack Overflow questions. So it might just be the 50 most difficult-to-learn rising programming technologies!)
Interpreted high-level programming language for general-purpose programming
JavaScript library for building user interfaces
PHP web framework (“for web artisans”)
Data structures and data analysis tools for Python
Superset of JavaScript that adds static typing (“JavaScript that scales”)
On-demand cloud computing platform
The interface between two programs.
Cloud computing service
Commandline shell and associated scripting language
Mobile and web application development platform
Chart of the top 10:
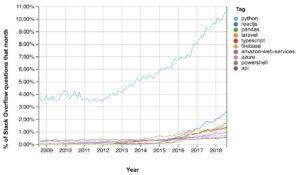
Python dwarfs everything else so here’s a look without Python:
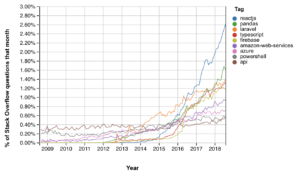
These tags were eliminated from the list solely on the basis of a 2018-only downward trend: R (would have been 2nd), Node.js (2nd), PostgreSQL (4th), numpy (12th), Express (14th), Apache Spark (14th), Tensorflow (18th), nginx (20th), Github (21st), Amazon EC2 (31st), ECMAScript 6 (39th), ffmpeg (46th)
python-3.x actually makes second place on the list but I rolled it into Python rather than make a redundant entry.
Django and Django Models were eliminated from the list despite being on an upward trend because they have not yet exceeded their previous peak in 2010. This resurgence, Pandas in fourth place and the presence of tkinter on the list speaks to the general rising of Python.
Load all tags on StackOverflow by count descending.
Put each of them into StackOverflow Trends and judge by eye if they are currently trending up.
In the whole list of tags by count Python is sixth overall, Firebase (10th place in this list) is 90th, and CMake (50th) is 442nd.
This will bring up a GraphQL endpoint at http://localhost:8080/graphql and the GraphiQL query tool at http://localhost:8080/graphiql if you run ./gradlew bootRun
plugins {
id("io.spring.dependency-management") version ("1.0.6.RELEASE") // Pull in dependencies automatically.
id("org.jetbrains.kotlin.jvm") version ("1.3.10")
id("org.jetbrains.kotlin.plugin.spring") version ("1.3.10")
id("org.springframework.boot") version ("2.1.0.RELEASE")
}
tasks.withType(org.jetbrains.kotlin.gradle.tasks.KotlinCompile::class.java).all {
kotlinOptions {
freeCompilerArgs = listOf("-Xjsr305=strict") // Enable strict null safety.
jvmTarget = "1.8"
}
}
repositories {
mavenCentral()
}
dependencies {
implementation("com.expedia.www:graphql-kotlin:0.0.23") // Generate GraphQL schema directly from code.
implementation("com.graphql-java-kickstart:graphiql-spring-boot-starter:5.1") // Get the /graphiql page for free.
implementation("com.graphql-java-kickstart:graphql-spring-boot-starter:5.1")
implementation("org.springframework.boot:spring-boot-devtools")
testImplementation("org.springframework.boot:spring-boot-starter-test")
}
package {yourpackagehere}
import com.expedia.graphql.schema.SchemaGeneratorConfig
import com.expedia.graphql.TopLevelObjectDef
import com.expedia.graphql.toSchema
import com.fasterxml.jackson.module.kotlin.KotlinModule
import graphql.schema.GraphQLSchema
import graphql.schema.idl.SchemaPrinter
import graphql.servlet.GraphQLErrorHandler
import graphql.servlet.GraphQLInvocationInputFactory
import graphql.servlet.GraphQLObjectMapper
import graphql.servlet.GraphQLQueryInvoker
import graphql.servlet.ObjectMapperConfigurer
import graphql.servlet.SimpleGraphQLHttpServlet
import javax.servlet.http.HttpServlet
import org.slf4j.LoggerFactory
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.boot.web.servlet.ServletRegistrationBean
import org.springframework.context.annotation.Bean
@SpringBootApplication
class Application {
private val logger = LoggerFactory.getLogger(Application::class.java)
@Bean
fun schema(): GraphQLSchema {
val schemaConfig = SchemaGeneratorConfig(
supportedPackages = listOf("{yourpackagehere}"),
topLevelQueryName = "YourQuery",
topLevelMutationName = "YourMutation"
)
val schema = toSchema(
queries = listOf(TopLevelObjectDef(YourQuery())),
mutations = emptyList(),
config = schemaConfig
)
println(SchemaPrinter().print(schema))
return schema
}
@Bean
fun graphQLObjectMapper(): GraphQLObjectMapper = GraphQLObjectMapper.newBuilder()
.withObjectMapperConfigurer(ObjectMapperConfigurer { it.registerModule(KotlinModule()) })
.withGraphQLErrorHandler(GraphQLErrorHandler { it })
.build()
@Bean
fun graphQLServlet(
invocationInputFactory: GraphQLInvocationInputFactory,
queryInvoker: GraphQLQueryInvoker,
objectMapper: GraphQLObjectMapper
): SimpleGraphQLHttpServlet = SimpleGraphQLHttpServlet.newBuilder(invocationInputFactory)
.withQueryInvoker(queryInvoker)
.withObjectMapper(objectMapper)
.build()
@Bean
fun graphQLServletRegistration(graphQLServlet: HttpServlet) = ServletRegistrationBean(graphQLServlet, "/graphql")
}
fun main(args: Array) {
runApplication(*args)
}
<canvas
class="chart"
data-type="horizontalBar"
data-labels="["White", "Blue", "Black", "Red", "Green", "Colorless"]"
data-series="[13, 11, 5, 2, 2, null]"></canvas>
$('.chart').each(function () {
var id = $(this).attr("id"),
type = $(this).data("type"),
labels = $(this).data("labels"),
series = $(this).data("series"),
options = $(this).data("options"),
ctx = this.getContext("2d");
new Chart(ctx, {
'type': type,
'data': {
labels: labels,
datasets: [{
data: series
}]
},
options: options
});
});
Recently we had an issue with very long-lived locks on certain rows in MySQL/MariaDB. Certain people (each row representing a person) would get locked out of updates for hours at a time. Using Flask/uWSGI/MariaDB/mysqldb.
SHOW ENGINE INNODB didn’t report any recent deadlocks or other issues but SHOW PROCESSLIST showed some very long sleeping processes and when these were killed the locks would go away. SELECT trx_started, trx_mysql_thread_id FROM information_schema.innodb_trx t JOIN information_schema.processlist p ON t.trx_mysql_thread_id = p.id; was also interesting showing some unclosed transactiosn that corresponded.
We seem to have cleared the problem up by explicitly closing the database connection on teardown_request.
Even with AUTOCOMMIT off a DROP TABLE or CREATE TABLE statement will cause an implicit commit in MySQL.
So if you drop your table of (say) aggregated data and then create a new one even if you’re theoretically in a transaction there will be time when clients of the database see no table and time when they see an empty table.
The solution is to use RENAME TABLE.
CREATE TABLE replacement_table (...) AS SELECT ... FROM ...; CREATE TABLE IF NOT EXISTS current_table (id INT); -- Just in case this is the first run and the table doesn't exist yet so RENAME TABLE doesn't fail. RENAME TABLE current_table TO old_table, replacement_table TO current_table;
No client of the database will ever see a database that doesn’t contain an existing and populated current_table.
I managed to get vim in the terminal using the system clipboard by using a version compiled with +clipboard and using set clipboard=unnamed in .vimrc. But I wanted to go one further and have the last entry in my emacs-like kill-ring in bash go to the system clipboard too. So that when I hit Ctrl-k on the commandline I can Cmd-v that text into my text editor (or anywhere). Turns out this is pretty tricky.
The best solution I have so far is courtesy of user3439894 on the Apple Stack Exchange. It requires me to use Ctrl-Shift-k to kill instead of Ctrl-k but otherwise does what I want pretty well. You can find the gory details at https://apple.stackexchange.com/a/336361/301884.
On pennydreadfulmagic.com we use a bunch of unicode symbols for everything from pagination (←→) to tagging external links (↑) to indicating that a specific card has a bug (🐞).
Lots of these symbols are present in the glyphs of our main body text font. But some are not. These rely on the system of the viewer to display. Sometimes they look ugly and sometimes they aren’t present at all and get the ugly square box treatment.
To work around this I want to supply a font that provides versions of the glyphs that aren’t present in the base font. But something fonts like Symbola that provide complete coverage of unicode start at about 1.5MB and go up. That’s a high price to pay for a handful of symbols!
One solution is font subsetting. You can make a version of a font that only contains the symbols you are going to use. It will be much smaller. Our subsetted version of Symbola is more like 15KB as an inline woff in the CSS file. A big saving.
You can subset fonts online very simply with the super useful Transfonter.
This unfortunately won’t do much good as a PR because the project seems to be abandoned but you can get really big speedups in pystache by caching templates and (particularly) parsed templates. Especially if you are using a lot of partials.
It looks something like this:
# Subclass pystache.Renderer to provide our custom caching versions of pystache classes for performance reasons.
class CachedRenderer(pystache.Renderer):
def _make_loader(self) -> pystache.loader.Loader:
return CachedLoader(file_encoding=self.file_encoding, extension=self.file_extension, to_unicode=self.str, search_dirs=self.search_dirs)
def _make_render_engine(self) -> pystache.renderengine.RenderEngine:
resolve_context = self._make_resolve_context()
resolve_partial = self._make_resolve_partial()
engine = CachedRenderEngine(literal=self._to_unicode_hard, escape=self._escape_to_unicode, resolve_context=resolve_context, resolve_partial=resolve_partial, to_str=self.str_coerce)
return engine
# A custom loader that acts exactly as the default loader but only loads a given file once to speed up repeated use of partials.
# This will stop us loading record.mustache from disk 16,000 times on /cards/ for example.
class CachedLoader(pystache.loader.Loader):
def __init__(self, file_encoding: Optional[str] = None, extension: Optional[Union[str, bool]] = None, to_unicode: Optional[StringConverterFunction] = None, search_dirs: Optional[List[str]] = None) -> None:
super().__init__(file_encoding, extension, to_unicode, search_dirs)
self.templates: Dict[str, str] = {}
def read(self, path: str, encoding: Optional[str] = None) -> str:
if self.templates.get(path) is None:
# look in redis using modified date on filesystem of path
self.templates[path] = super().read(path, encoding)
# write to redis
return self.templates[path]
# If you have already parsed a template, don't parse it again.
class CachedRenderEngine(pystache.renderengine.RenderEngine):
# pylint: disable=too-many-arguments
def __init__(self, literal: StringConverterFunction = None, escape: StringConverterFunction = None, resolve_context: Optional[Callable[[ContextStack, str], str]] = None, resolve_partial: Optional[StringConverterFunction] = None, to_str: Optional[Callable[[object], str]] = None) -> None:
super().__init__(literal, escape, resolve_context, resolve_partial, to_str)
self.parsed_templates: Dict[str, pystache.parsed.ParsedTemplate] = {}
def render(self, template: str, context_stack: ContextStack, delimiters: Optional[Tuple[str, str]] = None) -> str:
if self.parsed_templates.get(template) is None:
# look in redis
self.parsed_templates[template] = pystache.parser.parse(template, delimiters)
# store in redis
return self.parsed_templates[template].render(self, context_stack)
Following the Swiss Pairings Algorithm I wrote in python using weighted maximum matching I ported the blossom algorithm code to PHP.
This is a direct conversion of Joris van Rantwijk’s python code with the same tests and the same output.
The algorithm is taken from “Efficient Algorithms for Finding Maximum Matching in Graphs” by Zvi Galil, ACM Computing Surveys, 1986. It is based on the “blossom” method for finding augmenting paths and the “primal-dual” method for finding a matching of maximum weight, both due to Jack Edmonds.
Some ideas came from “Implementation of algorithms for maximum matching on non-bipartite graphs” by H.J. Gabow, Standford Ph.D. thesis, 1973.
A C program for maximum weight matching by Ed Rothberg was used extensively to validate this new code.
https://github.com/bakert/blossom-php/blob/master/mwmatching.php